基本概念
本系统提出一种高效、稳定、易维护的系统集成方法,其核心思路是把一个系统的接口调用过程抽象成任务节点,把系统业务集成过程抽象成流水线,通过流水线把多个任务节点串联起来。
为方便阅读对以下名词进行解释:
应用: 代表完成的哪两个系统之间的集成,如:ERP对接财务软件。
流水线: 代表集成的业务,一个应用下面对应多条流水线,如:“财务软件的存货档案同步到ERP”, “ERP的销售出库单同步到财务系统”等。
任务节点: 代表一个系统的接口调用,一条流水线上有多个任务节点,如:“财务软件的存货档案同步到ERP”这条流水线包括“获取财务软件存货档案”任务节点和“存货档案写入到ERP”两个任务节点。
模型: 任务节点返回的数据可以转换为模型,模型可作为流水线的下一个任务节点的输入参数进行传递,参见(模型解析算法)
这里流水线 是系统的核心概念,系统集成就是为不同的流水线设置不同的调度策略,而开放平台则是把流水线通过接口的方式开放出去,如图所示:
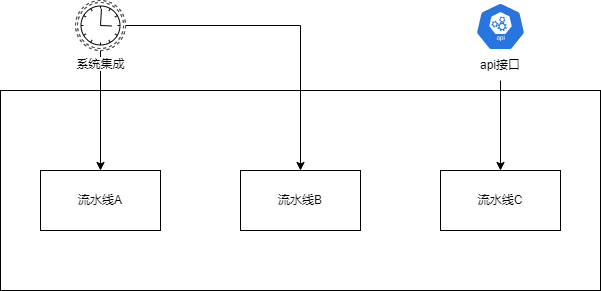
# 开发第一条流水线
重要
在开发之前应先确保对业务已经非常了解、然后根据各系统的开放能力确定调用接口,然后在确认接口输入输出参数是否满足业务需要,所有的都搞清楚以后在进行开发
这里我们拿"金蝶商品同步到自有商城"进行举例 设计: 目前已知金蝶提供了商品查询接口、自有商城提供了商品写入接口,又因金蝶系统在调用接口之前需要提前登录,故此流水线流程为:
登录-->获取金蝶商品-->商品写入到自用商城
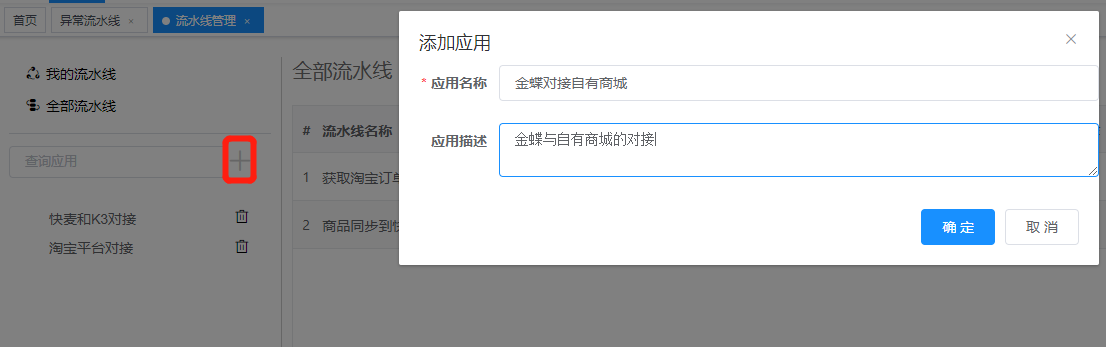
# 创建应用
打开流水线管理点击创建应用,如下图:
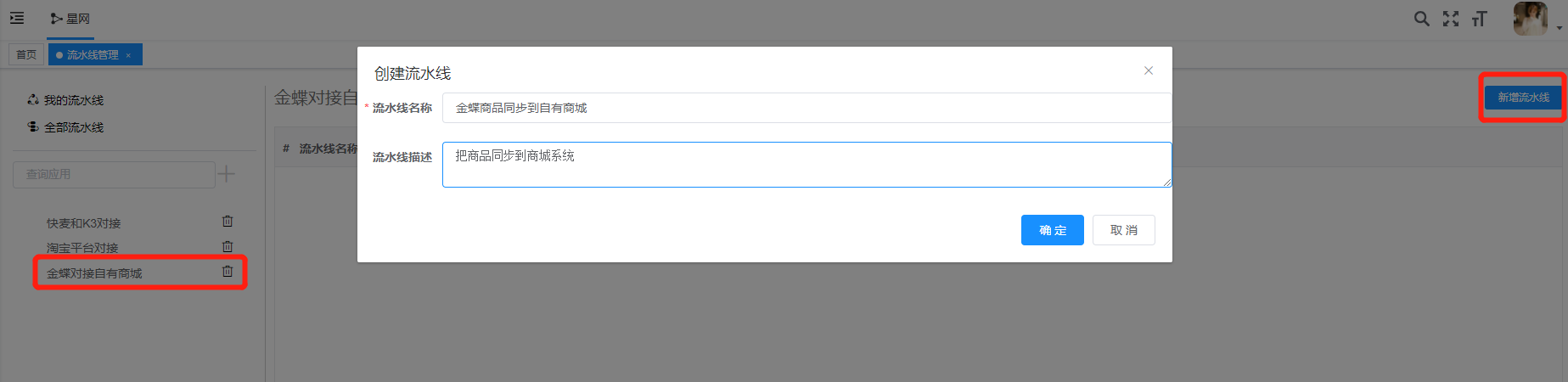
# 创建流水线
在金蝶对接自有商城应用下新增流水线,如下图:
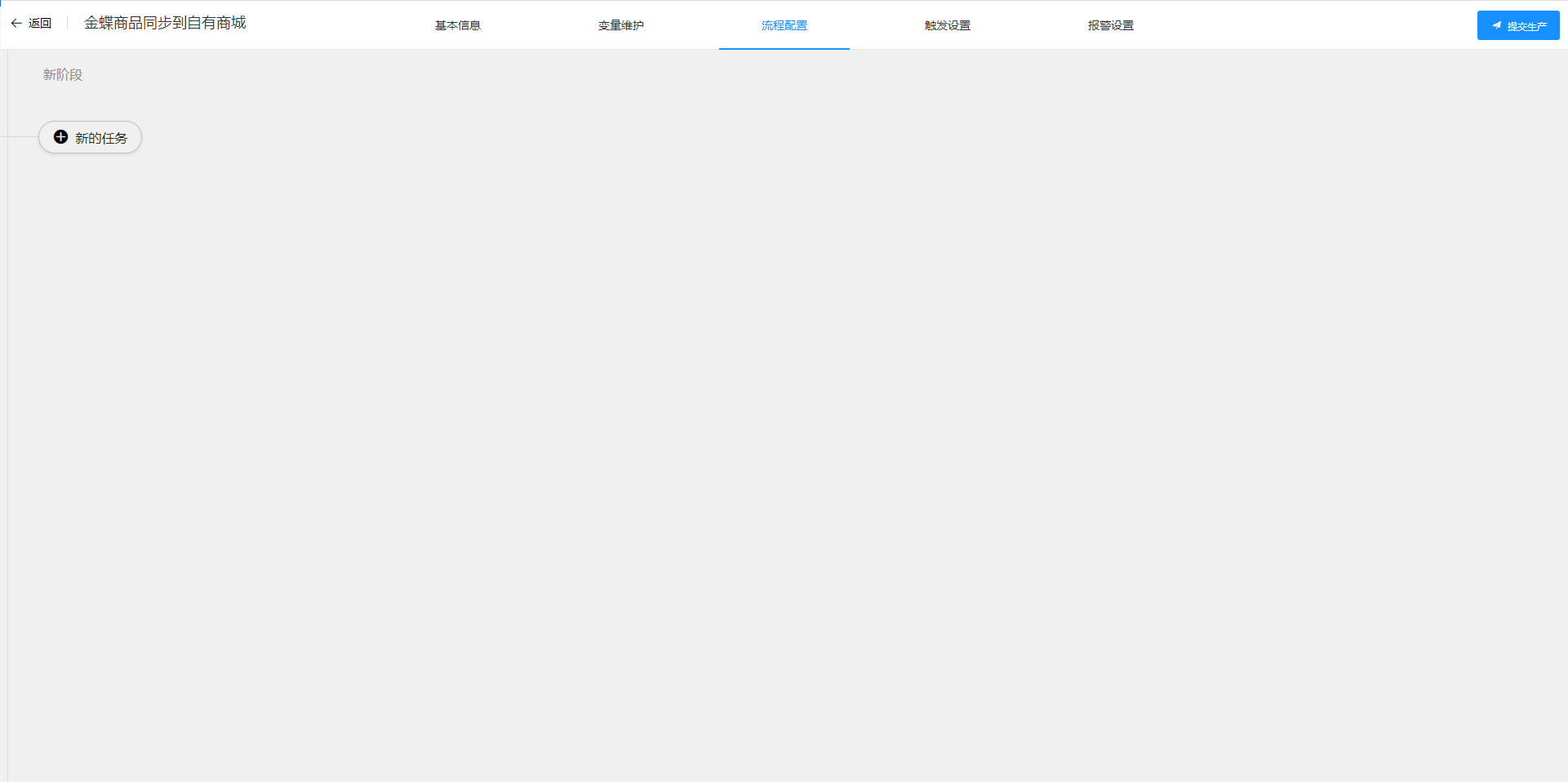
# 编辑流水线
创建流水线后会进入流水线编辑页面,如下图:
# 添加任务
点击添加任务,如下图:
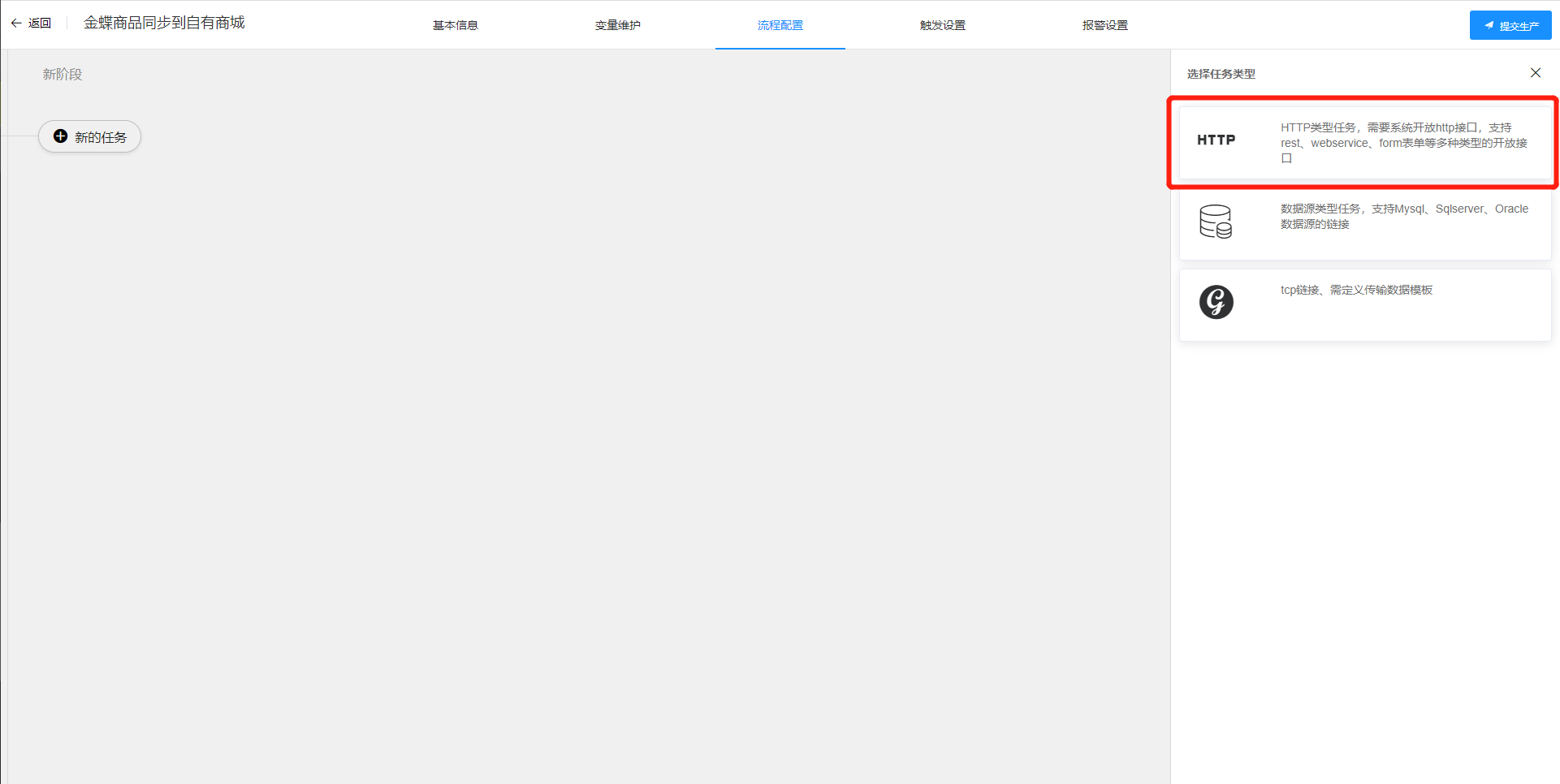
目前系统仅支持HTTP任务,也就是说待对接的系统必须开放HTTP协议才能实现调用
# http任务编辑
根据接口的要求配置HTTP任务
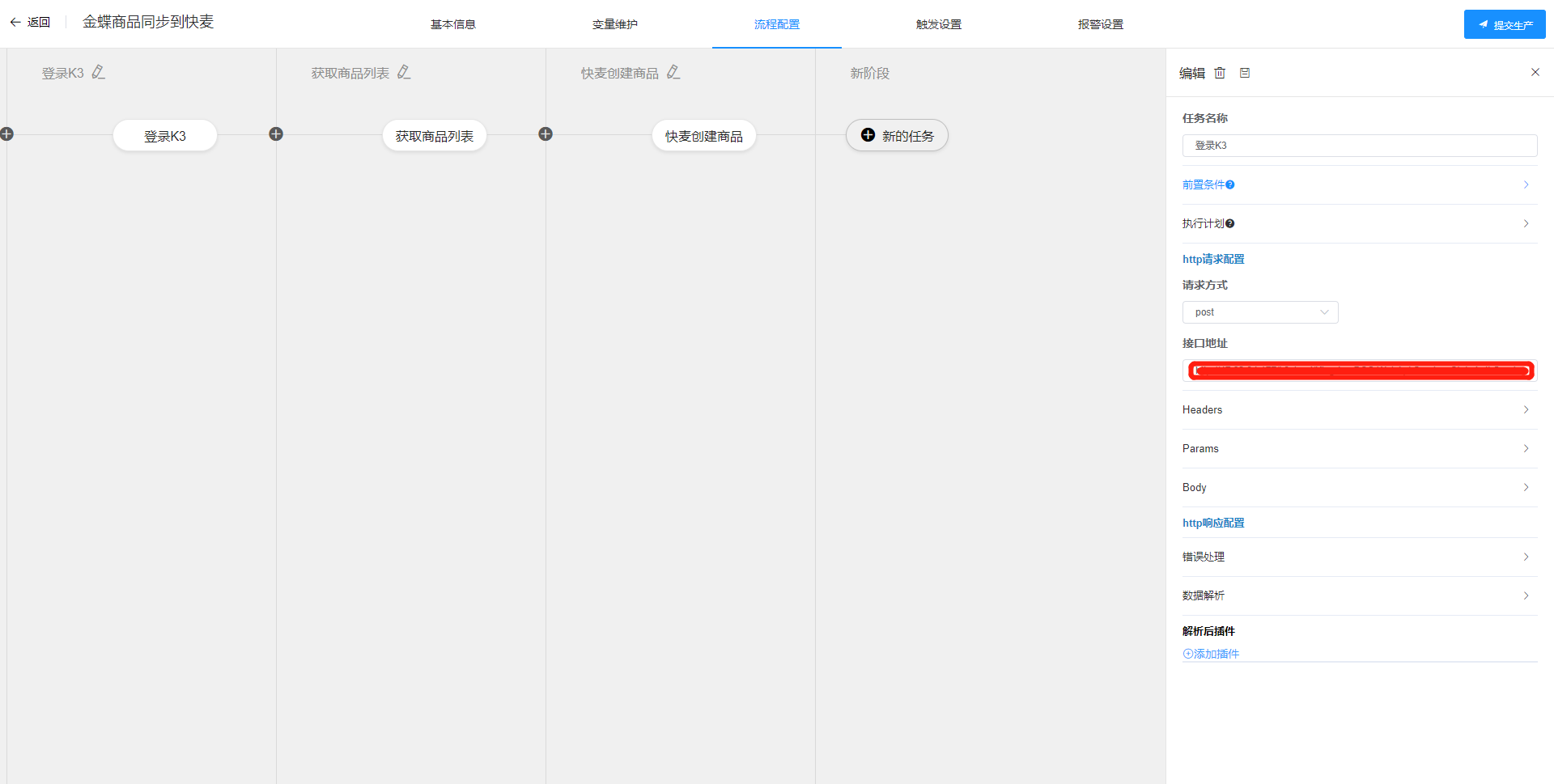
一个HTTP任务有前置条件、执行计划、请求配置、响应配置及部分组成
# 前置条件
前置条件是指当前任务执行的前置条件,目前前置条件支持表达式,可根据业务要求设置不满足条件所触发的逻辑。
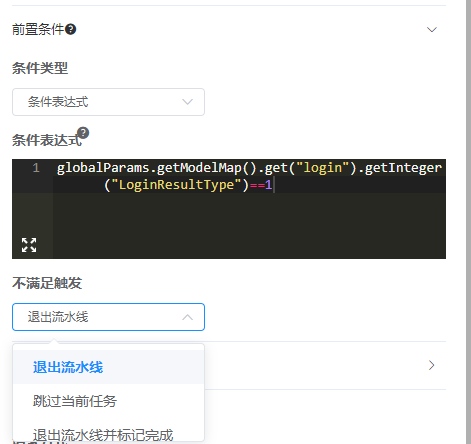
触发逻辑:
退出流水线 :条件不满足退出此流水线,流水线运行状态为失败状态
跳过当前任务 :条件不满足不执行当前任务
退出流水线并标记完成 :条件不满足退出此流水线,流水线运行状态为成功状态
# 执行计划
执行计划是指当前任务已何种方式执行,总体概括分为顺序执行和循环执行
☆顺序执行 :
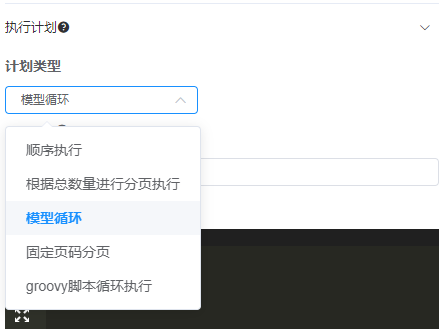
解释:执行一次当前任务
☆根据总数量进行分页执行 :
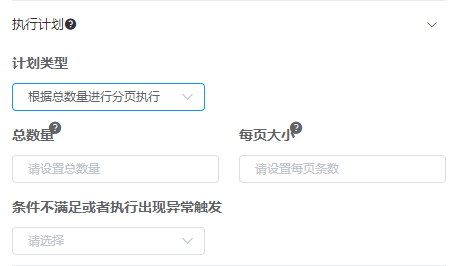
解释:
总数量:引用值,一般引用上一个任务的执行结果,如引用订单的总数量:#{order.total}
☆根据数组模型循环 :
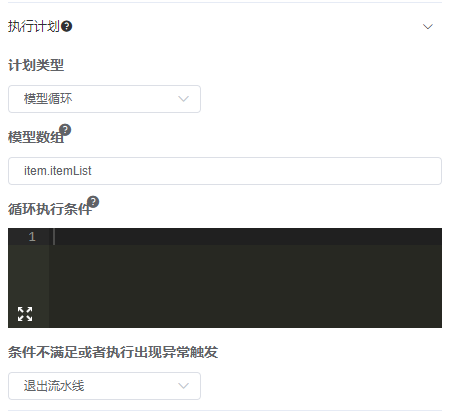
解释:
模型数组 :引用值,一般引用上一个任务的执行结果,如引用订单列表:order.orderList
循环执行条件 :校验当前模型是否允许执行,如已付款的订单才会执行,表达式如下:object.getString("status").equals("pay"),其中object指当前订单,
status为订单状态
条件不满足或者执行出现异常触发 :当前模型执行条件不通过或者执行过程中出现异常后的触发逻辑包括:
退出流水线: 退出流水线,流水线运行状态为失败
退出当前任务:退出当前任务,流水线的下一个任务继续执行
跳过本次:执行列表中的下一个模型
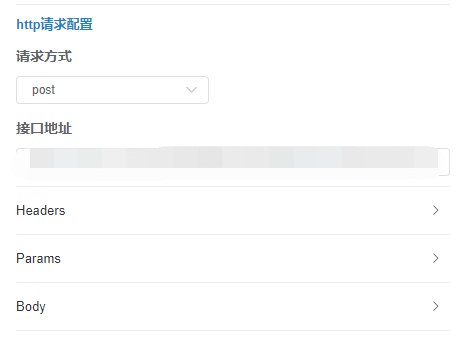
# 请求配置
根据被调用接口的要求设置,设置项包括请求方式、接口地址、headers、params、body
# 响应配置
http调用成功后对响应结果的处理,包括错误处理、数据解析两个步骤
错误处理 :
被调接口返回的错误提示的处理,如接口返回如下
{
"error_response":{
"msg":"Remote service error",
"code":50,
"sub_msg":"非法参数",
"sub_code":"isv.invalid-parameter"
}
}
则我们需要根据具体返回的内容做相应的处理,错误处理有三个解析器:分别为JSON解析器、Xml解析器、脚本解析器
# 错误解析器-json
场景:接口返回的数据格式为Json,配置示例如下:
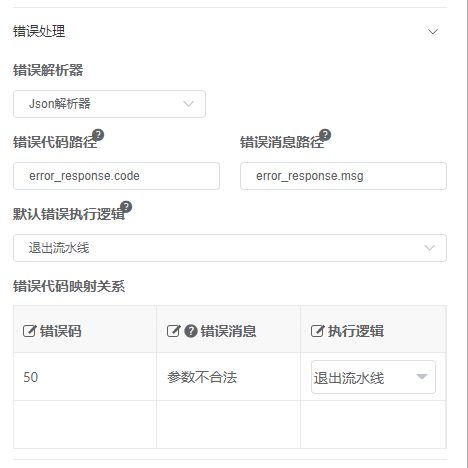
解释:
错误代码路径: 返回JSON的哪个节点可以表述当前接口调用是错误的,在上面的例子中错误节点是error_response.code
错误代码映射关系:当接口返回的错误码等于设置的值时我们的处理逻辑,触发逻辑如下:
✳✳ 退出流水线: 退出流水线,流水线运行状态为失败
✳✳ 退出当前任务:退出当前任务,流水线的下一个任务继续执行
✳✳ 先重试,重试仍然失败则退出流水线:先重试一次重试失败后退出流水线,流水线运行状态为失败
✳✳ 先重试,重试仍然失败则退出当前任务:先重试一次重试失败后退出当前任务,流水线的下一个任务继续执行
✳✳ 正常返回:当前接口调用正常,执行后续的数据解析
# 错误解析器-xml
场景:接口返回的数据格式为xml,配置和json解析器相同
# 错误解析器-脚本
场景:接口返回的数据不是json或者xml则使用此解析器,配置示例如下:
配置代码如下:
import cn.w2n0.interconnection.domain.node.entity.ErrorMessageParser;
import cn.w2n0.interconnection.domain.node.entity.ErrorMessageResult;
/**
* @author 无量
* @date 2021/12/30 15:25
*/
public class GrovvyTest implements ErrorMessageParser<String> {
@Override
public ErrorMessageResult parser(String body) {
ErrorMessageResult errorMessageResult=new ErrorMessageResult();
errorMessageResult.setLogicType(ErrorLogicType.eixtFlow);
errorMessageResult.setMessage("系统错误退出流水线");
errorMessageResult.setSuccess(true);
return errorMessageResult;
}
}
上述代码中body是我们我们接口返回的报文信息
数据解析 :
对被调接口返回的内容进行处理,如接口返回如下
{
"trades_sold_get_response":{
"request_id":"52*****ax08",
"total_results":"35849",
"trades":{
"trade":[
{
"no_shipping":false,
"oaid":"**************a0EgWQXYBCsPEzx8nfjN5LuzRPjs4toa26bcLotDC*************",
"tid":"2364*************06"
}
]
}
}
}
数据解析器有两种类型:
1.解析为模型
包括格式化为模型(配置)、格式化为模型(脚本) 两个解析器
场景:
当前接口返回的接口会作为下一个任务节点的输入参数的情况下使用,如把平台A的订单推送给平台B,平台A提供了订单查询接口,平台B提供了订单写入接口,在配置平台A时解析类型需要选择格式化为模型(配置)或者格式化为模型(脚本)
2.返回消息
包括格式化为模型并返回、脚本格式化消息并返回、直接返回原始数据,共三个类型
场景:
开放网关业务用到,用来屏蔽下游接口的差异
WARNING
系统集成项目中数据解析一般不会用到返回消息
# 数据解析器-格式化为模型(配置)
场景:接口返回的数据格式为Json、xml,配置示例如下:
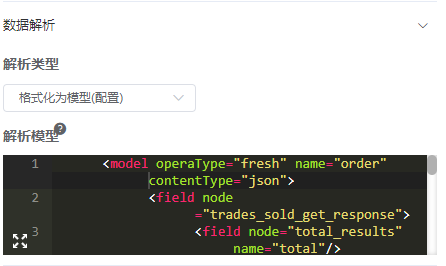
作用: 通过配置规则把接口返回的内容转化为自有业务模型。最终建立企业标准化业务域。
名词解释-业务域
业务域的使用能帮我们搭建标准化的对接流程,假如我们需要集成一个财务系统,那么我们可以预先建立标准财务实体模型,而后基于财务实体模型实现财务系统的对接。 通过建立业务域能使我们的系统更加稳定,比如财务系统因外在原因需要由K3切换成U8这时我们只需要做好U8和我们标准业务与的适配即可
解析模型demo:
假设,平台返回的原始报文是
{
"trades_sold_get_response":{
"request_id":"52*****ax08",
"total_results":"35849",
"trades":{
"trade":[
{
"no_shipping":false,
"oaid":"**************a0EgWQXYBCsPEzx8nfjN5LuzRPjs4toa26bcLotDC*************",
"tid":"2364*************06"
}
]
}
}
}
我们希望转换后的业务模型为
{
"total":"35849",
"orderList":[
{
"deliver":false,
"orderNo":"2364*************06"
}
]
}
则我们的配置如下:
<model operaType="fresh" name="order" contentType="json">
<field node="trades_sold_get_response">
<field node="total_results" name="total"/>
<field node="request_id"/>
<field node="trades">
<field node="trade" name="orderList" objectType="array">
<field node="no_shipping" name="deliver"/>
<field node="tid" name="orderNo" master="true"/>
</field>
</field>
</field>
</model>
解释:
model 属性
| 参数 | 是否必填 | 说明 |
|---|---|---|
| name | operaType不为current时必填 | 模型名称,被引用时使用 |
| operaType | 是 | 1.fresh:创建新模型(要求模型名称在流水线中唯一) 2.current:当前节点为循环模式时的item 3.flow:更新已执行流水线模型 Fresh 客户手动创建 |
| contentType | 是 | 规则解析器类型,可选值: 1.json:接口返回为json时使用 2.xml:接口返回为xml时使用,一般应用于webservice接口 |
field 属性
filed支持父子关系,采用约定优先原则,父子关系与定义的模型以及返回的模型的父子关系有关!
node:表示原始返回信息中JSON或者xml的节点,非必填
name:标识自定义名称,非必填
master:主键节点
objectType:节点类型,可设置为array,当前定义的模型属性强制定义为对象数组对象时有意义,如果接口返回的node已经是对象数组则当前节点自动为数组类型,非必填
expression:表达式,当前模型属性的值是由多个node计算出来时用到,表达式为java代码片段,如:
<field name="memo">
<expression>
JSONArray jsonArray=json.getJSONObject("trade").getJSONObject("orders").getJSONArray("order");
String memo="";
for (int i = 0; i< jsonArray.size(); i++) {
JSONObject rspObj = jsonArray.getJSONObject(i);
memo+=rspObj.getString("refund_status");
}
return memo;
</expression>
</field>
# 数据解析器-格式化为模型(脚本)
场景:接口返回的数据格式不为json或者xml时使用,解析模型如下:
import cn.w2n0.interconnection.domain.node.entity.MessageModelParser;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import java.util.Map;
public class K3ItemCount implements MessageModelParser<String> {
@Override
public void parse(String body, JSONObject object, Map<String, JSONObject> modelMap) {
JSONArray jsonArray= JSON.parseArray(body);
int size = jsonArray.size();
JSONObject jsonObject=new JSONObject();
jsonObject.put("total",size);
modelMap.put("item",jsonObject);
}
}