# 分页读取单据
场景
获取某段时间内某平台的订单信息。
说明
平台提供了订单查询接口,请求参数和响应参数如下:
输入参数:开始时间、结束时间、页号、分页大小,其中页号是从第0页开始,分页大小最大是100条,且时间为修改时间(增量时间)。
响应结果:返回JSON格式,json中包含订单列表和查询总条数
响应格式如下:
{
"trades_sold_get_response":{
"request_id":"52*****ax08",
"total_results":"35849",
"trades":{
"trade":[
{
"no_shipping":false,
"oaid":"**************a0EgWQXYBCsPEzx8nfjN5LuzRPjs4toa26bcLotDC*************",
"tid":"2364*************06"
}
]
}
}
}
分析
1.因某段时间内的单据数量无法确定,如10分钟内有50单,但是活动期间10分钟内可能有500单;所以如果一段时间内的单量小于100则调用一次接口,否则按照不同的页码调用多次接口,如一段时间的单量为550单则至少需要调用6次接口。
2.因时间为增量时间,假设时间范围内的订单有550条如果从第0页开始一直到第4页结束;顺序调用的话则会出现漏单的情况,这是因为在下一页调用之前如果前几页已经调用过的订单发生变化则待调用的数据会前移到已经调用过的页码列表中这样后续的调用永远取不到这部分数据,但如果从第4页开始一直到第0页结束;倒序调用的话则不会出现此问题。所以获取一段时间的分页数据不能顺序调用或者乱序调用,只能倒序调用。
方案
在流水线中创建两个分组任务分别是获取订单列表和分页获取订单列表
# 获取订单列表
核心在数据解析上需要解析返回的总数量,代码如下:
<model operaType="fresh" name="order" contentType="json">
<field node="trades_sold_get_response">
<field node="total_results" name="total"/>
<field node="trades">
<field node="trade" name="orderList" objectType="array">
<field node="buyer_nick" name="buyer_nick"/>
<field node="tid" name="orderNumber"/>
</field>
</field>
</field>
</model>
# 分页获取订单列表
经分析如果时间段内的单据数量小于100则不进行分页执行,所以节点执行的前置条件如下:
globalParams.getModelMap().get("order").getInteger("total")>100
提示
分页获取订单列表的分页大小应与分页获取订单列表中的前置条件判断数量、分页大小数量完全一致
设置执行计划为“根据总数量进行分页执行” ,设置如下图:
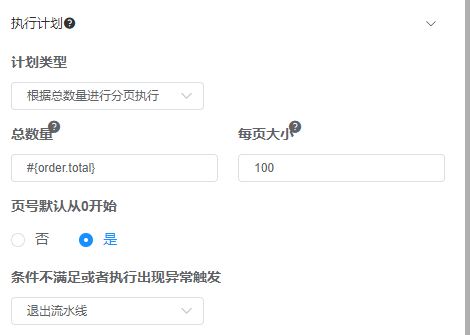
经分析分页获取应按页码倒序调用接口,因为获取订单列表任务中已经获取了第0页的订单所以在本任务中在获取第0页的数据时可能出现数据重复的问题所以应该设置订单编号为主键进行防重处理,配置如下:
<model operaType="fresh" name="order" contentType="json">
<field node="trades_sold_get_response">
<field node="trades">
<field node="trade" name="orderList" objectType="array">
<field node="buyer_nick" name="buyer_nick"/>
<field node="tid" name="orderNumber" master="true"/>
</field>
</field>
</field>
</model>
写到这里大家可能有两个疑惑
疑惑1:按照分析当前例子用分页调用6次接口就可以把所有单据获取出来,这里为什么要调用7次呢?
这是因为你不调用第一次时不知道单据的总数量的
疑惑2:既然获取订单列表已经读取第0页的数据了为什么分页执行还要调用第0页的数据呢?
这是因为数据在调用过程中可能已经发生变化,导致本来在第0页的数据跑到下一个时间段了,进而导致非0页的数据重新分配到了第0页,所以必须重新获取第0页的数据才能保证数据的完整性。
思考:
对于获取一段时间内的单据列表能否使用分布式调用?如果仔细阅读并思考本文章相信您一定有一个明确的答案!
如果一段时间内的订单量非常大,比如100W单,如果单机调用的话整个数据获取将会非常缓慢,有什么方案解决呢?拆分时间进行分布式调用